Get PageSpeed 100 by using W3 Total Cache and Autoptimize, Part 3: Page Cache
Configure Page Cache Settings of W3 Total Cache plugin
This is the third post in our series that explains how to set up W3 Total Cache plugin to achieve PageSpeed grade of 100.
Here we explain how to configure the Page Cache Settings of W3 Total Cache plugin.
The Page Cache Settings page has many sections, and we shall consider them one by one.
The screenshots from the Settings pages that you see here, are taken from narrow screens, to allow this post to be seen on narrow screens properly. These Settings pages on wide screens look a little bit differently, and we give links to the relevant screenshots.
General section 
Here you indicate which dynamic/navigational pages you want to be cached: posts page, front page, feeds.
Individual posts and pages are always cached with the exception of the front page that you may exclude from caching by checking the second box.
I have indicated my choices but you should mark it in accordance with your needs. If some page is not cached then its creation will take longer time and its PageSpeed grade will suffer due to longer server response experienced by the Google robot. Thus, if you want Google search to display your page, make sure it is cached.
View the wide screen version of this part of the Settings page.
{kind=link}
 Secure pages and query strings: I do not mark these two.
Secure pages and query strings: I do not mark these two.
View the wide screen version of this part of the Settings page.
{kind=link}
 File not found: I suggest not marking it as we are not concerned with the speed or search visibility of File not found pages. The only remaining reason to cache them is to reduce the server load but I think it is not worth the trouble that may be caused by incorrect response code.
File not found: I suggest not marking it as we are not concerned with the speed or search visibility of File not found pages. The only remaining reason to cache them is to reduce the server load but I think it is not worth the trouble that may be caused by incorrect response code.
View the wide screen version of this part of the Settings page.
{kind=link}
 Cache only my site address: I have marked it although it does not seem to have much difference. I think that here the question concerns pages that are accessed not through your website address but rather through your server address and server path; on my current configuration, I do not know whether my public pages can be accessed this way.
Cache only my site address: I have marked it although it does not seem to have much difference. I think that here the question concerns pages that are accessed not through your website address but rather through your server address and server path; on my current configuration, I do not know whether my public pages can be accessed this way.
View the wide screen version of this part of the Settings page.
{kind=link}
 Don’t cache pages for logged in users: check, this is important. If you uncheck it and open your page while being logged in as an admin, the page you see – with the admin bar on the top – may be cached and served to strangers. They will see the admin bar on the top even though they are not logged in. The links on the admin bar will not work, though.
Don’t cache pages for logged in users: check, this is important. If you uncheck it and open your page while being logged in as an admin, the page you see – with the admin bar on the top – may be cached and served to strangers. They will see the admin bar on the top even though they are not logged in. The links on the admin bar will not work, though.
View the wide screen version of this part of the Settings page.
{kind=link}
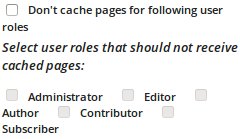 User roles: After you have checked the previous box, this one should not matter.
User roles: After you have checked the previous box, this one should not matter.
View the wide screen version of this part of the Settings page.
{kind=link}
Cache Preload 

I suggest configuring this as indicated on this screenshot. The reasons are as follows.
The purpose of cache preload is to have cached pages ready to be served when requested. In particular, you may want to serve cached pages to the Google bot that comes to your site daily, to make sure it thinks that your site is fast.
However, I have not been able to make this functionality to work properly. In fact, in my experience it more often retires existing cache than creates the new one.
With my recommended settings as shown on this screenshot, this still happens, and I also set a cron job to refresh cache as explained below.
View the wide screen version of this part of the Settings page.
{kind=link}
Setting the cron job to preload the caches
Why cron job
Users are served cached pages only if these cached pages exist and are up to date.
According to my experience, W3 Total Cache purges cached pages once in a while. With the settings I suggested above, this happens on my site every few days.This happens when some spammer (or a spam bot) tries to leave a comment and Akismet plugin blocks this comment as a spam. This has also happened to me when I deleted the spam comments for certain pages; at this moment the cache for all these pages was purged. Note that the spam comments do not show on pages and for this reason the pages do not really change when the spam comments are left or deleted; nevertheless, W3 Total Cache plugin purges the cache in such cases.
You can see this happening on your file manager at
wp-content/cache/page_enhanced/yourwebsiteaddress.com/
where you can see two files, index.html and index.html_gzip which are the cache of your front page (if you marked it to be cached), and a directory for each of your cached pages and posts which contains two files with the same names, index.html and index.html_gzip . When W3 Total Cache retires its cache for a page, it appends .old extension to these filenames. When the next user asks for a page, a new version is created and cached; you can see that the timestamp of the cache files changes and the .old extension disappears.
If your site has already a lot of traffic, only a small portion of users will be affected, and they will just have to wait maybe a second or two for your page, depending on the speed of your server.
However, if you do not yet have that much traffic and want to make sure that Google bot gets your pages quickly on its daily visits then you may want to take an action to make sure that cache is always preloaded.
Cron is a Linux/Unix scheduler. We set it to request your pages from your server on a regular basis. Whenever the cached version of your page or post is retired, the next scheduled request will cause the server to create it again.
If your cache is up to date then this job will just serve that cache and this is usually a light task not adding significantly to server load.
How to set it up
The simplest way to set it up on your server itself; you can do this if your service provider gives you access to the cron jobs on the server.
(If your server provider does not give you access to cron jobs on the server, you may set up this job on any other computer including your home one. Bear in mind that if that computer is down then the job does not run and the cache is not preloaded. The directions I give, are valid for Linux machines only; Windows and Mac have similar tools.)
I have set this job to run every 15 minutes. In this way the chance that Google bot will come before the cache is preloaded, appears to me small although I have noticed this happening once when this job ran every 30 minutes.
You should ask your server provider for directions how to access cron jobs. Some providers give special tools for that and some may just give you SSL shell access to the server. In the latter case you can follow these directions for setting your cron jobs from the command line.
The cron job I set, is just one long line:
wget -O – http://baruchyoussin.com/; wget -O – http://baruchyoussin.com/sitemap; …
Instead of my site you should list yours, and the continuation of this line should list all pages and posts whose cache you want to preload.
Here wget is the command that downloads a remote file, and -O - instructs it not to save the file it downloads but rather to print it out to STDOUT which is discarded as the goal of our request to the server is to rebuild the cache rather than to get the file. (If you set your server to send you an email with the results of each cron job, you will get these files by email so better avoid this.)
Purge policy 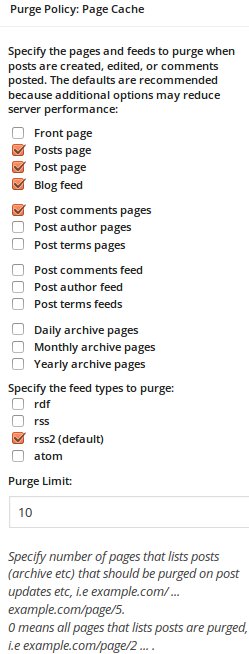
If one of your posts is created or changed then you may want to update the contents of various pages that contain summary information, to reflect the change.
To make this update happen, you need to purge the existing cache of that page; the next request will create the new page which will be then cached. (The next request may come from the above cron job if you set it.)
This section indicates which pages you want to purge in such cases. The pages you do not mark to be purged, will stay stale until they are purged some other way.
I went with the default settings, with one exception.
 Under Additional pages: I deviated from the default settings.
Under Additional pages: I deviated from the default settings.
Initially I gave there the address of my site map: sitemap . (My site map is created by Simple Sitemap plugin.)
The reason is that the default regexp that appears in the following field, Purge sitemaps:, does not catch my site map for the reason I do not understand.
This is how this section of the Settings screen looks on a wide screen.
{kind=link}
 Eventually I decided upon an alternative approach (see the additional screenshot) not to purge the sitemap on the publish events. The point is that on my site I am the only person who publishes new posts and pages, and it is easy for me to update the site map manually in such cases. On the other hand, most of the publish events are spam comments which cause unnecessary purging of the site map even though these comments are blocked.
Eventually I decided upon an alternative approach (see the additional screenshot) not to purge the sitemap on the publish events. The point is that on my site I am the only person who publishes new posts and pages, and it is easy for me to update the site map manually in such cases. On the other hand, most of the publish events are spam comments which cause unnecessary purging of the site map even though these comments are blocked.
Advanced
Here I went with the default settings with one exception.
I changed Garbage collection interval: to 0 although I am not sure it has any effect.
Stuart says:
If your hosting provider doesn’t allow setting cronjobs, there are some services, that will allow cronjob up to each 10 minutes for free, like easycron.com.